Soloing a 1 person student startup
Lessons from relern

Thoughts after building something people want…
These are my collected thoughts from having gone through the process of marketing, building, and then selling relern—the fastest and easiest MCP tool that allows agents to interact with your Canvas classes. Just my raw collected thoughts. Nothing else.
It was all chaotic; that is the short answer. Would I do it all again? No, lol.
I added this snippet from Solo Founders.
I really wouldn’t say that I closed out this segment of relern well, in a sense. We were doing okay—not great in comparison to what other startups were doing (I’m talking startups grossing $70k+/month), but okay. I decided to close out this chapter not from the push of other people, but because I had grown tired of managing what was essentially a one-person startup.
Pure burnout is the short answer.
Growth was moderate. We were getting tons of user feedback and had completed a pivot from providing a complete modified agent harness to just the core tool of what people loved. Briefly getting into the weeds: one of the interesting novel things we pushed out was a useful tool called “report_broken_tool” that would allow models to quickly post error telemetry data (what tool was attempted, styling format, sequence of what tools were being used, case, rough overarching task like assignment completion, reading a textbook, accessing messages, etc.) and give us as the end builders at relern what broke, where it broke, why it likely broke, and the sequencing to replicate the failure. This was a pretty good rollout, as it allowed us to move faster on seeing where slippage on our core product failed rather than waiting for users to post bugs. It also allowed us to see which tools were being used the most and make them much faster, while also seeing which tools failed to fix them (or have a team of agents resolve the issue autonomously).
I think that this singular tool is likely going to become more prevalent as people continue to build out tools and use cases of how tools or interfaces are interacted with—not for humans, but for agents.
Same with taking the long-term memory–based scratchpad/knowledge-base architecture hinted at in model research papers from the major labs.
I guess I should start from the beginning….
The beginning
It was the summer of 2025, and I was finishing up my junior year of college at Penn State. I’d just found out from my academic advisor that I could have graduated earlier that spring (I missed a couple emails regarding signing up for graduation), and I’d been toying around with a couple ideas.
That spring, I had basically almost completely vibe-coded most of my classes, in essence for my core CS classes. I had set up a framework for Cursor agents to interact with my CS work on GitHub (I’d fork, then tell agents to go into my GitHub and look at the repo) and set a series of instructions for them to complete the assignment. They did it surprisingly well.
I think I got an A- in most of my final-year classes—end of junior year, summer ‘25 (I registered for summer courses to demo relern), and fall ‘25. But I was also toying with having models interact with web content. The big buzz from the Valley was the rollout of browser use, which was popular in the summer of ‘24, and we saw the terrible rollout of the AI agent browsers in the fall of ‘24 and spring of ‘25.
Claude 3.5 (upgraded Sonnet), fall ‘24, had just come out—pre/post DeepSeek R1 timeline—so let’s set the baseline at when Claude 4 Sonnet dropped in May 2025.
I’d seen students using tools to interact with their courses, but it was super slow, and models really only needed to interact with the given browser to click and type content. Everything else didn’t need a model to be fully using the browser.
For those reading this, the first generation of browser agents were ultra slow. I’m talking about the OG browseruse/browserbase products, and they weren’t that reliable.
Now, most software tools that serve large user bases—think Twitter, Facebook, Zillow, Reddit, AWS, GCP, Google’s products—have existing APIs that are interactable.
Instructure, the parent company of Canvas, has an API, but models couldn’t yet call them easily.
The first version
Basically, the first version of relern was an N8N clone where users dragged and dropped workflows of what they wanted agents to do.
Yes, this was the spring/summer of ‘25. R1 was just kinda there, tool calling was still kinda fresh, Claude 4 had just come out (less than a week old). That was when the price war on intelligence was just starting out.
I made a very basic site where people could temporarily add their Canvas tokens and freely use a mixture of models to complete academic tasks that they set out. Still, everything was very manual; it required humans (users) to define everything that the model would do. These weren’t even the days of “long horizon” tasks, or for those ideas to be baked into models yet really—at least not on the lower end of smaller/mini models.
I was also playing around with having models fetch things, but things were still very manual.
The bottleneck was the final-stage items: writing a response, posting a reply to a discussion, fetching content that was restricted from a student’s Canvas, and, biggest of all, what would a model do with this info, really? A student would still have to take what models produced and actually complete the tasks there. The problem was the “last mile” finisher of tasks students cared about.
So I spun up a very basic pitch to acquire more users. As of then, I only had two: myself and one of my college friends. It was a very basic Browserbase demo where we had a browser model sign into a student’s quiz/exam items and literally click around and “complete” an exam.
I’ll link to it if I didn’t add a GIF of it here, but mind you, this was still May/June 2025.
I then used that simple video to crash into NY Tech Week and demo to interns. I also asked a ton of my friends to let me into their GCs for where they were interning and if I could showcase what I was building!




Pricing and validation
One thing I did right in the early stages: when people asked me, “How much is it?” I just priced it at higher and higher tiers to see where sentiment was at. I started off at $10, then $25, then $50, $75, and the price that people were okay with paying (I think maybe because this was the upper end of student earners, and getting paid $55–85/hr, you don’t really care if a tool costs a higher premium if it works) before breaking off at ~$175.
I found this very interesting. More of the problem was validated: “Tools that allow for AI models to complete your classes for you.” Something this simple would devolve to be very complex. Foreshadowing.
By early July, I had about 700 people who had signed up. I manually emailed updates along the way and for when I’d release a beta to try out.
Ramp Economics Lab HQ for their intern event I got a ton of signups. basically if there was an intern networking party or free thrown event catered towards interns/new grads in the city I was there
Building
I took the summer off, thinking, okay, I have just this last summer before I’d graduate. Finding a role wasn’t too difficult if I failed. I was hung on just solving the problem well.
The first version of anything isn’t really perfect. Nothing is.
I built a local MCP server people could download for free. Being in the tech space helped a ton, as most students using relern were SWE interns, so asking someone to open a terminal and install the MCP on their machine locally wasn’t difficult. From the first set of initial people that signed up, a small amount tested it out. There was a large mixture of interns in growth, tech, finance, grad students, new grads that still had friends in college, etc. Not everyone could justify installing a local MCP. So we (I) went back to the drawing board again on how to further simplify things to make it easier.
Network effects matter and are what allowed us to scale to our first 1,000 users. Everything after that was pure virality and UGC.
By the end of the summer of ‘25, we had settled into building out a web version of relern. It’d be much easier, and we could control the entire end-to-end experience. So we dashed to make it. We released it mid-fall ‘25, and the adoption curve was much better compared to the initial hard manual launch. By the end of winter ‘25, we had converted most of our 700 signups into using the web version, and 2,500+ people in total had signed up or indicated interest! But things were still fairly clunky, and I didn’t want to fully release it to the masses just yet and let the floodgates open.
I also graduated that fall.
But we kept the momentum. We polished the full product, rolled it out, and by then, from simple word of mouth and the momentum of the spring semester starting, we had crossed the 1,000-user threshold.
Solo founder reality
How you go from 0 to 1 is vastly different in each increment: 1–100, 100–1,000, and so on. Or at least each step function requires a different way of how to go about it.
I should also mention: running a semi-solo AI startup by yourself at this point isn’t fun. This is really just pure founder advice in general. You can’t really go to your friends who work full time in industry, or to those in academia, or even your parents.
I’ll place this excerpt here, as it basically stood out during the entire process. I’d find it very hard trying to explain to my close friends from college why relern worked and what happened under the hood.
“The idea interested me, then inspired me, then captivated me. It seems so obvious. So simple. So potentially huge. It’s been weeks and weeks on this paper. I’d moved into the library, devoured everything I could find about importing and exporting, about starting a company. Anyway, I’d given a formal presentation of the paper to my classmates who reacted with boredom. You know what? Not one asked a single question. They greeted my passion and intensity with sighs and vacant stares. The professor thought my crazy idea had merit; he gave me an A, but that was that. At least I was supposed to think that. I had never really stopped thinking about that paper. So two thoughts pop to mind when I read that. First, at least I got an A. If you remember somewhere back in the Ep. #150s, I covered the biography of Fred Smith, the founder of FedEx. His company also started as a term paper and he got a C. But the second thing I thought of was one of my favorite ideas that I learned from Edwin Land, the founder of Polaroid. I’ve done, I don’t know, five or six books on Edwin Land, five or six podcasts on him. Anyways, he said something very interesting. He says, the test of an invention is the power of an inventor to push it through in the face of staunch—not opposition, but indifference—in society. In a way, to reduce the thought, or the main point behind Edwin Land’s quote, is that indifference is your enemy. And we saw the same thing in the end. The presentation that Phil was giving—they didn’t hate the idea, they just didn’t care about it at all.”
— Founders Ep. #186 (Phil Knight), Shoe Dog, and the story of Nike’s origin
I quickly realized that explaining to close friends and family what I was doing was, and is, hard—especially explaining the compulsion to build something that can help someone else’s life be much easier. It’s not that they didn’t care. They just didn’t really understand why I’d go through the entire process of building something like this out. My dad thought I was going crazy. Laughing at this in hindsight—in some parts he was right.
I’d get questions like:
Why spend $14k+/month all for people to use AI with their classes?
What are tokenomics?
Why do you care about helping people complete their classes faster?
Isn’t it easier to just go do anything else?
Why not just go all in and work full time at a regular job?
On the other side were my entrepreneurial and technical friends who were building things out, as well as mentors who understood the unlock that occurred, value add, etc. These people were a godsend, as without them I wouldn’t have realized when to call it quits and do something else, or when to change things.
Big ups to Kai, Danny, James, Shevy , and so many other mentors during this entire process, plus Santi.
Growth engines: knowing when to pivot to what your customers actually want vs. what you want to build
This alone could actually resolve probably 90% of failed/ing startups that have a good idea, but execution is half-half. Now, to understand the 90%, all you have to do is look at the 10% and you get why. E.g., your movie passes, lol.
In the early days, it’s about building out a solution that just works to lightly solve a problem for someone. You only have to focus on two simple things:
Is this what people want?
Does this solve their problem?
Don’t become a hammer looking for a nail, but I’m presuming that most of those reading this already know this. In the process of building out the most basic form of that hammer, you don’t need to worry too much about stuff like weight distribution, coloring, maximizing grip strength, telling users the optimal way to swing, etc.
Those will emerge naturally if something actually solves a problem someone has, and they’ll create communities.
People will talk to each other, share problems that they’ve had and how your hammer helped, and give you feedback—but usually 9 out of 10 times it’s if the hammer doesn’t work and where you could fix it.
Early power users shape a product but shouldn’t fully define it, or else you get caught in a trap of basically only serving that specific niche. It becomes harder to broaden the TAM, and slippage may occur when you choose to simplify and reduce the number of features available and just make a good product that loops into itself and creates the funnels necessary to grow.
Virality loops and UGC
We were still doing UGC. From friends in the startup space—more so from engaging with founders in the consumer tech space—they indicated that UGC was where I should divert my attention. Word of mouth was still kicking in, and it worked, but that growth engine had slowed drastically to a trickle as the spring semester started to chug along quietly (remember, I graduated, so it was watching my users).
I made a few videos initially, but you obviously learn what you’re good at.
I’m a good coordinator, builder, and customer support manager. Not a content marketing genius. So I outsourced, mostly paying independent student creators to not only become users but serve as the marketers for relern.
Initially, I hired creators based on the data I had: an 82/16 split on male:female users, what year, etc. I didn’t really reach the stage where I signed long-term contracts with the content creators that produced stellar content. But the virality engine was starting to churn.
Btw, TikTok/Instagram was where the majority of the new users were coming from. Not Snapchat or LinkedIn. More so because most of the early intern group chats I was in were on Instagram, and we all sent each other reels/TikToks, so it’s where I knew that’s where the targeted base was at.
Now, mind you, I was still paying for this out of pure savings.
The costs
February was a scary month, as that was when I got my first bill of >$8k from OpenRouter.
March was even scarier, as that one was even larger at about $14k.
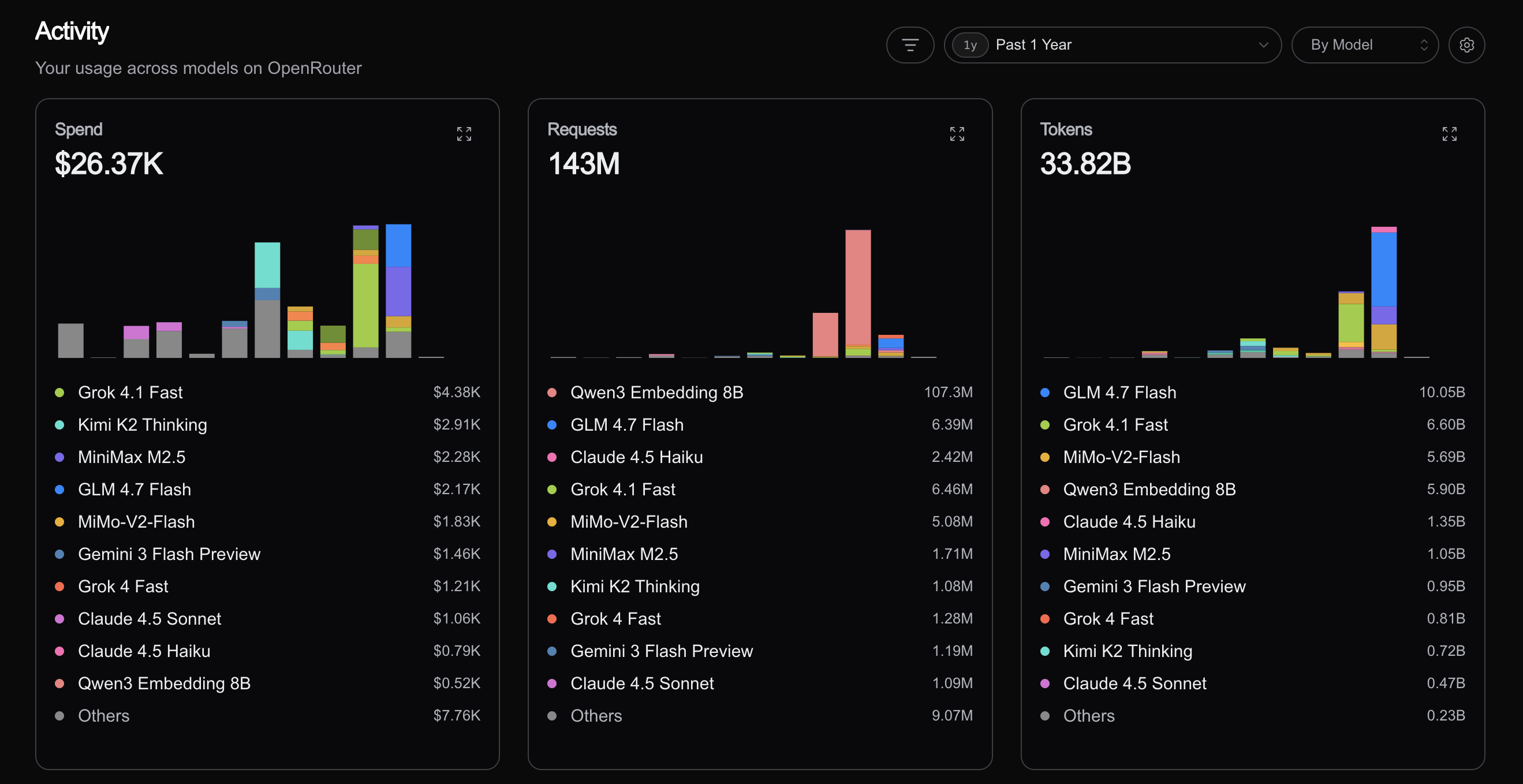
This was on top of paying creators about $130 per video (usually I’d request two videos from a given creator and give it about a week to a week and a half, posting on a Monday at 11 a.m., as that was when demand would start to track and the ed-tech rec engine on TikTok/Instagram would start to kick in, sending to users’ feeds, then repost the same video again on Thursday morning).
If the video quality was garbage, I’d usually not post it. You can actually just message creators to remake it, though this only happened once, and that was because I didn’t set the clear directionality of what style of video I wanted the creator to make. I presumed that their best judgement would suffice, but not so much (working with students is hard, lmao). They redid it, and it was good enough to test once.
Knowing when a format just works
This fuels virality engines. When you hit a fast-moving airstream, then try and glide for as far and long as possible.
We had one video that was just a simple “come with me to hang out with my friends while my class agent does my work.” It was less on the product and more on what the creator would do if they didn’t have their schoolwork. It blew up to about 102k views and converted a ton of people, which was nice.
Safe to say we did end up rehiring that creator a few more times in the months to come before the sale!
The pivot
Okay, I was foreshadowing a bit. This part is a bit more technical, or “technical lite.” Backtracking a bit, we pivoted late February/early March as we got feedback from one of our whales who was using us a ton (this guy just stalked me on X and messaged me, lol). He wanted to use relern with openclaw to get as hands free of an experience as possible, similarily the Claude app with CoWork had just come out, Notion rolled out Notion agents (very early days in the beta for notion agents there were less than 400 of us), etc. but I posted on X to make a more polished easier to integrate version of relern available. a few people responded on the feedback which was nice so I pressed on.
“Knowing when to pivot to what your customers actually want”—this was it.
So we went back to the drawing board. We pushed out a short Q&A that was a simple yes-or-no to all our users via email: “Do you want to use relern on Claude/Codex/Cursor for free?”
Most responded yes. A few people wanted to know how their pricing would fall out if they already paid, etc. I ended up keeping the month of March open for users who paid or were on the free tier to keep using. Although by mid-March, we had already migrated most of our users to their own AI tools they used, and gave notice that our core harness would be deprecated and we’d move to supporting using relern in most AI tools.
That month, I refunded all of our paying users to the tune of $18k in total and ate the cost of the $14k bill we got from OpenRouter.
We used up something like ~19bn tokens alone in March, which in itself is a ton of data to use. also switched to other models sporadically under hte hood for A/B testing to see if model similarity on benchmark scoring truely affected user experience… e.g. swapping claude haiku 4 for kimi 2.5 or GLM 4.7/5
The grind
I don’t know if you can tell by now, but it was really just me going about everything. I was also working full time as an intern at Google through this entire process. Some days I’d not sleep at all and would churn through my work like a drone. Go home and crash to sleep at 6 p.m. and wake up at about 2 a.m., work through the entire morning, and then head to the office.

Would I do it again solo? Fuck no.
The sale
April was big. I was finishing up my internship. Obviously, managing a FT internship and also doing a startup that would have closed about $216k solo was a pretty good achievement. But that was much less than my total comp at Google FT if I joined as an L3/L4 with less stress.
So I started looking for buyers. I was hinting at it and found a few startups that were interested.
*this is a pro tip for founders, do not look for a quick sale, these things take months. the communities I went to had low traction. acquired/microsaas/ a few other platforms aren’t taht great and sellers are less personable and I got bad reviews.
I went down the route of just sending emails & booking calls directly to founders in the ed-tech niche that had something similar to what relern was. I was at the point where it was less of wanting to sell and more of wanting to have the flexibility and backing of a larger team to cross the barrier for scale. though at the same time I was burnt out with the idea of working in the space.
I joined tons of meetings, explained what relern was, the pivots, margins, growth areas and opportunities—basically to sell the idea and infra more than anything else. We had a couple of cool tech items we laid out:
Courserank: Our own version of Google’s PageRank algorithm that indexed everything a student did, looked for changes, and stored them in our own systems so that models could index items faster. You could spin up 50 agents to tranch through material on a student’s Canvas without getting flagged.
Document processor: We built our own document processor using off-the-shelf items so that we didn’t face the high pricing of LlamaParse and the only-PDF nature/limited set of file types you could send to models. There was no built-in document processor on Claude AI/Notion/Cursor web agents, etc., so we made it a tool that models could call for all content types. If the model was interacting with a PDF or an item that was linked, then the sandboxed env would process the document and return it to the model.
Model scratchpad: AI agents would have their own notebook to leave for future models on completing assignments—what was done, why, links, helpful reasoning items that would help if they found it useful. Basically a changelog of why certain assignments or tasks were done a certain way, if there was feedback from an instructor on the work that the student did, message items, hints from instructors, students, or previous/concurrent models, etc.
Report_broken_tool: This allowed models to quickly post error telemetry data (what tool was attempted, styling format, sequence of what tools were being used, case, rough overarching task like assignment completion, reading a textbook, accessing messages, etc.) and give us, as the end builders at relern, what broke, where it broke, why it likely broke, and the sequencing to replicate failures.
This was a pretty good rollout, as it allowed us to move faster on seeing where slippage on our core product failed, rather than waiting for users to post bugs. It also allowed us to see which tools were being used the most (for Courserank) and make them much faster, while also seeing which tools failed to fix them—or have a team of agents resolve the issue autonomously—as I was still operating as a one-man solo startup!
There were a ton of other tools that helped make relern easy to use and to provide use telemetry, not just in the product, but for growth and customer success, as I was answering customer questions, resolving bugs, managing creators, and defining what was important. All while working full time.
Then the end of April hit. :) One YC company did accept my acquisition price!
Waiting on escrow brokerage to clear, as these things take time to close out and for final items to finish/help them integrate things into their system, so updates when that happens. But updates in a month or early June.
But on the non-sensitive info: I sold relern for much less than what I would have expected to make by the end of 2026. To the tune of, if the math was right, I sold for about 15% of the value of what it was worth
AI startups are money hungry, and in my case, needing to hire more staff, grow, etc.
It wasn’t an amount that I can lay on the beach and sip piña coladas all day with, but it was enough to pretty much satisfy me to the point where I could fully self fund graduate school. I understand this, some people may argue and say, “you could have sold for 320k+ but I wanted out. I just wanted to recalibrate life a bit.
*For those saying you could have pressed on, “sure yeah”. Phil knight pressed on but that was his life mission for building out nike. Imagine burning 2/3 of your savings and someone says to keep pressing forward for a marginally entrenched market. Being a founder sucks, it’s not for the faint of hearted. sure I recouped what I made back what I lost but it’s more so to at what cost. I’ll address these questions a bit later.



Simplicity ended up being king, it's what users cared about in the end. not fancy harnesses, or code modes to save us as the providers means of token spend/usage, just something to connect the tools they already use with their classes.
Always keep it simple or atleast don't overcomplicate things. You really don't need something that is crazy or super sophisticated
*Or as David Senra from @FoundersPodcast would probably harp, “just take this complex idea and make it ridiculously simple”
Questions I didn’t answer yet
Could I have fundraised? Or did you consider fundraising?
Yes, I could have actually (hindsight is I probably should have). I avoided it, though. There were several funds (angel partners, 27v, and a few others) and angel investors (founders involved around the NYC area that thought what I was building was cool) that wanted to invest in more of me specifically rather than the idea.
But I didn’t want to fundraise money, then tell investors, “Hey, this is a very money-hungry business that I barely have an idea of a profitable business model for, and reaching scale is scary for me. I’m not the type of person to manage a team of more than 20+ people before things get hectic, and I have no cofounder. I work better as a CRO or CPO, and I’m burnt out on the idea a bit, and there are better things to work on.”
But from one of my mentors, he just said, it’s okay if the idea falls flat; it’s a bet on the people at these early stages. But it is what it is.
Could you have pivoted again and done maybe an RL lab?
This question was asked by a few people on Reddit for the r/entrepreneurs and r/SaaS subreddits.
Pivoting to become an RL lab is too much work, and I don’t have the skills to be a good leader in that space, nor do I know where all too much to begin. I’m technical, but not that technical at all. And I don’t think users would like their data being leveraged like that. It feels slimy in a way. So no from me.
Closing thoughts
But yeah, that’s how to go from 0 to 100: from being a student → founder → back to being an individual contributor/student again.
The next three years from now, I’ll be 24 by then. Maybe if I stuck it out with the idea, we’d have moved from my initial hope of 30k users to the base case of what I presented in pitch meetings of 78k users of relern as the tipping point, though I only saw us cross 3.4k users at peak. The company I sold to does have a sizable user base of about 2M users, so safe to say users of relern are in safe hands.
I’ve got a month and a half of my true “last summer,” which is just a continuity of my final semester of college: day drinking, reading, debating researchers online, and messaging/chatting with interesting people that are peculiar, before I start work and school full time again. (I like stress in hindsight; it’s like an old abusive ex that you miss and go back to.)
I’m at Cornell now, so pop over and say hi.
Uhhh, post questions (on this Substack if you’re reading this on Substack) or shoot me a message if you want more details or have more questions.
Hindsight, I’ll finish with this statement
“And those who urge entrepreneurs to never give up? Charlatans. Sometimes you have to give up. Sometimes knowing when to give up, when to try something else, is genius. Giving up doesn’t mean stopping. Don’t ever stop. Luck plays a big role. Yes, I’d like to publicly acknowledge the power of luck. Athletes get lucky, poets get lucky, businesses get lucky. Hard work is critical, a good team is essential, brains and determination are invaluable, but luck may decide the outcome. Some people might not call it luck. They might call it Tao, or Logos, or Jñāna, or Dharma. Or Spirit. Or God”
― Phil Knight, Shoe Dog (the founding story of Nike)